复合校验与布隆过滤器实践
2025/9/19大约 5 分钟
比如在高并发系统中,用户注册是一个典型的高风险操作:
- 同一个手机号可能被重复提交
- 数据校验逻辑复杂
- 数据库频繁查询可能成为性能瓶颈
为了应对这些挑战,本篇笔记总结了 复合校验(Composite Check) 和 布隆过滤器(Bloom Filter) 在注册场景中的应用实践。
1️⃣ 注册方法解析
以 register(UserRegisterDto userRegisterDto) 方法为例:
@Transactional(rollbackFor = Exception.class)
@ServiceLock(lockType=LockType.Write, name = REGISTER_USER_LOCK, keys = {"#userRegisterDto.mobile"})
public Boolean register(UserRegisterDto userRegisterDto) {
// 执行用户注册前的复合校验检查
compositeContainer.execute(CompositeCheckType.USER_REGISTER_CHECK.getValue(), userRegisterDto);
// 数据库操作
User user = new User();
BeanUtils.copyProperties(userRegisterDto, user);
user.setId(uidGenerator.getUid());
userMapper.insert(user);
UserMobile userMobile = new UserMobile();
userMobile.setId(uidGenerator.getUid());
userMobile.setUserId(user.getId());
userMobile.setMobile(userRegisterDto.getMobile());
userMobileMapper.insert(userMobile);
// 布隆过滤器添加手机号
bloomFilterHandler.add(userMobile.getMobile());
return true;
}核心功能点
事务保证(@Transactional)
- 保证用户表和手机号表操作原子性
- 异常回滚,避免部分数据写入
服务锁(@ServiceLock)
- 防止高并发下重复注册
- 锁粒度基于手机号
2️⃣ 复合校验(Composite Check)
什么是复合校验?
复合校验是一种 将多种校验策略组合在一起的模式,通常使用 Composite + Strategy 设计模式 实现:
- 每种校验逻辑是一个独立策略(Strategy),继承
AbstractUserRegisterCheckHandler CompositeContainer负责扫描所有策略,按层级和顺序组装成组合树- 调用
execute(type, param)时,会依次执行所有策略 - 只要有一条策略校验失败,就抛出异常,终止注册流程
与简单接口策略不同,抽象类提供了 子节点管理、递归执行和公共方法,无需每个策略重复实现组合逻辑。
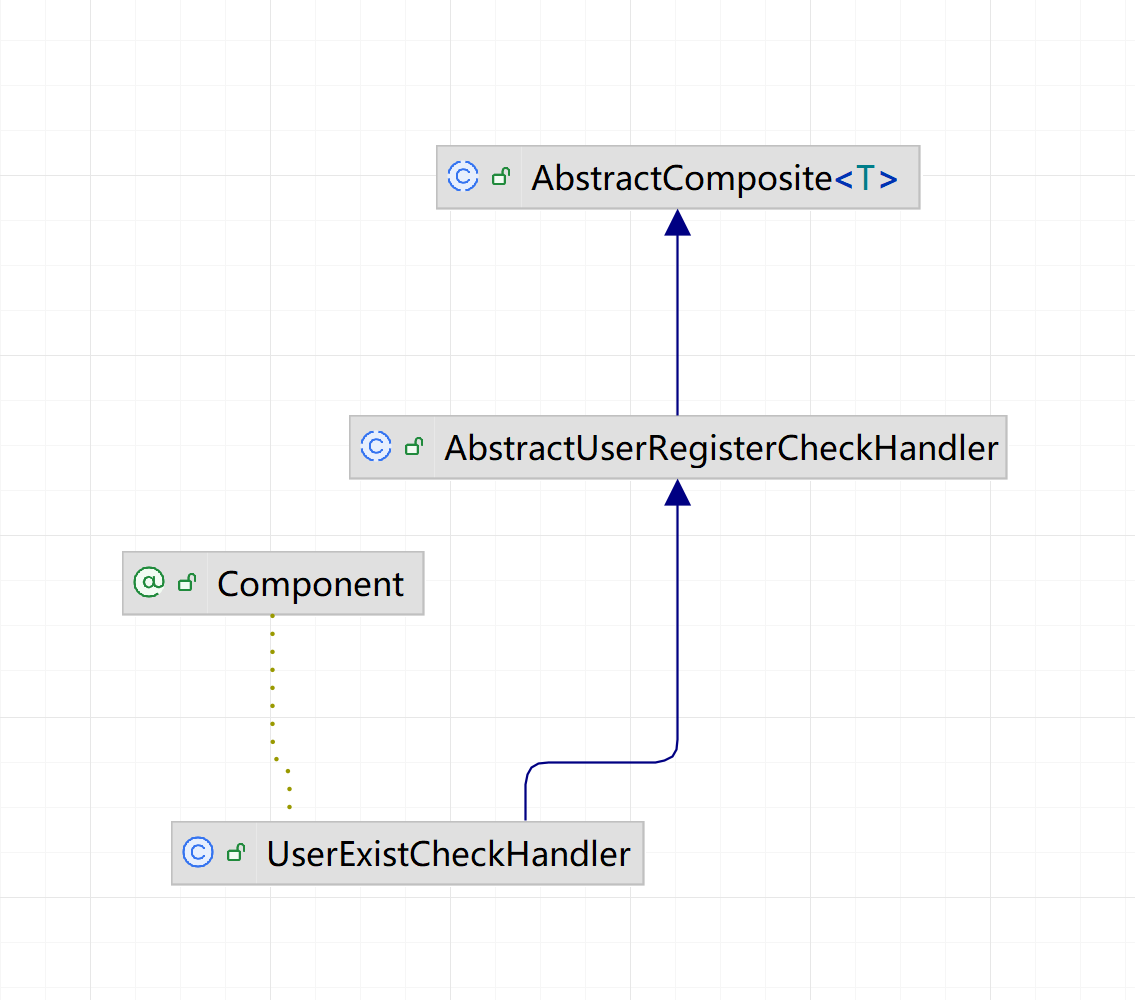
1️⃣ 类关系梳理
AbstractComposite<T> // 抽象组合接口基类
↑
│
AbstractUserRegisterCheckHandler // 用户注册校验抽象基类
↑
│
+------------------------------+
| 具体策略类(Strategy) |
| UserExistCheckHandler |
| UserRegisterVerifyCaptcha |
| UserRegisterMobileCheck |
| ... |
+------------------------------+
CompositeContainer<T> // 容器类,负责初始化和执行整个组合树AbstractComposite
- 定义了组合模式的通用结构,包括
list存储子节点、add()添加子节点、allExecute()层次遍历执行 - 提供抽象方法:
execute()、type()、executeParentOrder()、executeTier()、executeOrder()
- 定义了组合模式的通用结构,包括
AbstractUserRegisterCheckHandler
- 用户注册校验的抽象基类
- 固定了
type()返回值为USER_REGISTER_CHECK
具体策略类
- 每条校验逻辑继承自
AbstractUserRegisterCheckHandler - 实现
execute()方法完成校验 - 通过
executeParentOrder() / executeTier() / executeOrder()定义树形结构和执行顺序
- 每条校验逻辑继承自
CompositeContainer
- Spring 初始化时扫描所有
AbstractCompositeBean - 按
type分组并根据 tier/order 构建组合树 - 调用
execute(type, param)时,按层次遍历执行所有子策略
- Spring 初始化时扫描所有
2️⃣ 执行流程示意
假设注册流程中有三个策略:
- UserRegisterMobileCheck(手机号校验) tier=1, order=1
- UserExistCheckHandler(手机号是否存在) tier=2, order=2
- UserRegisterVerifyCaptcha(验证码校验) tier=1, order=2
组合树结构:
Root (tier 1)
├─ UserRegisterMobileCheck (order 1)
├─ UserRegisterVerifyCaptcha (order 2)
└─ UserExistCheckHandler (tier 2, parentOrder=1)执行顺序(层次遍历 BFS):
- Tier 1: UserRegisterMobileCheck → UserRegisterVerifyCaptcha
- Tier 2: UserExistCheckHandler
优势
| 特性 | 描述 |
|---|---|
| 高度解耦 | 每条校验逻辑独立实现,不耦合注册方法 |
| 易扩展 | 新增校验只需新增策略类并继承抽象基类,容器自动加载 |
| 复用性高 | 相同策略可复用于不同业务场景,如注册、修改手机号、找回密码 |
| 统一管理 | 抽象类和容器提供子节点管理、执行顺序和组合树结构,简化流程控制 |
| 高性能 | 可以轻松组合布隆过滤器、Redis校验等高效判断逻辑,减少数据库查询 |
3️⃣ 布隆过滤器(Bloom Filter)
什么是布隆过滤器?
布隆过滤器是一种 高效判断元素是否存在的概率型数据结构:
特点:
- 可能误判存在(false positive)
- 绝不会漏报不存在(no false negative)
示例:手机号存在判断
// 添加手机号到布隆过滤器
bloomFilterHandler.add(userMobile.getMobile());
// 检查手机号是否存在
if (bloomFilterHandler.exists(userRegisterDto.getMobile())) {
throw new BusinessException("手机号已注册(布隆过滤器判断)");
}在注册场景的作用
- 用户注册后,将手机号加入布隆过滤器
- 下次注册或验证手机号时,先通过布隆过滤器判断是否存在
- 如果布隆判断不存在,则直接写库;如果判断存在,再去数据库二次确认
- 减少数据库查询次数,提高性能
优势
| 特性 | 描述 |
|---|---|
| 高性能 | 内存中判断,避免频繁查询数据库 |
| 高并发适用 | 快速判断重复元素,防止重复注册 |
| 节省资源 | 使用位数组和哈希函数,内存消耗小 |
4️⃣ 总结
在用户注册功能中,结合 复合校验 + 布隆过滤器 可以有效解决:
- 业务校验复杂 → 复合校验解耦策略
- 重复注册风险 → 分布式锁 + 布隆过滤器
- 性能压力大 → 布隆过滤器减少数据库查询
通过这种设计,注册功能既保证了 安全性、正确性,也兼顾 高性能与高并发能力。
核心概念回顾
| 概念 | 描述 | 优势 |
|---|---|---|
| 复合校验(Composite Check) | 将多种校验策略组合成一个统一执行器 | 高度解耦、易扩展、复用性高 |
| 布隆过滤器(Bloom Filter) | 高效判断元素是否存在的概率型数据结构 | 减少数据库查询、高性能、高并发适用 |